平成30年秋期試験午後問題 問3
問3 プログラミング
⇱問題PDF
ウェーブレット木に関する次の記述を読んで,設問1~4に答えよ。
ウェーブレット木に関する次の記述を読んで,設問1~4に答えよ。
広告
ウェーブレット木は,文字列内の文字の出現頻度を集計する場合などに用いられる2分木である。ウェーブレット木は,文字列内に含まれる文字を符号化して,それを基に構築される。特に計算に必要な作業領域を小さくできるので,文字列が長大な場合に効果的である。
例えば,DNAはA(アデニン),C(シトシン),G(グアニン),T(チミン)の4種類の文字の配列で表すことができ,その配列は長大になることが多いので,ウェーブレット木はDNAの塩基配列(以下,DNA配列という)の構造解析に適している。
ウェーブレット木において,文字の出現回数を数える操作と文字の出現位置を返す操作を組み合わせることによって,文字列の様々な操作を実現することができる。本問では,文字の出現回数を数える操作を扱う。
〔ウェーブレット木の構築〕
文字の種類の個数が4の場合を考える。DNA配列を例に文字列Pを"CTCGAGAGTA"とするとき,ウェーブレット木が構築される様子を図1に示す。
ここで,2分木の頂点のノードを根と呼び,子をもたないノードを葉と呼ぶ。根からノードまでの経路の長さ(経路に含まれるノードの個数-1)を,そのノードの深さと呼ぶ。各ノードにはキー値を登録する。
図1では,文字列Pの文字Aを00,文字Cを01,文字Gを10,文字Tを11の2ビットのビット列に符号化して,ウェーブレット木を構築する様子を示している。また,図1の文字列の振り分けは,ウェーブレット木によって文字列Pが振り分けられる様子を示している。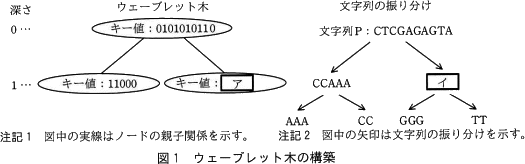 ウェーブレット木は,次の(1)~(3)の手順で構築する。
ウェーブレット木は,次の(1)~(3)の手順で構築する。
文字列P全体での文字C(=01)の出現回数は,次の(1),(2)の手順で求める。
与えられた文字列Q内に含まれる文字の種類の個数をσとするとき,あらかじめ生成したウェーブレット木を用いて,与えられた文字列内で指定した文字の出現回数を数えるプログラムを考える。ウェーブレット木の各ノードを表す構造体 Node を表1に示す。左の子ノード,又は右の子ノードがない場合は,それぞれ,left,right にはNULLを格納する。 文字列Qに対応して生成したウェーブレット木の根へのポインタを root とする。文字列Q内に存在する一つの文字(以下,対象文字という)をビット列に符号化して,整数(0~σ-1)に変換したものを r とする。
文字列Qに対応して生成したウェーブレット木の根へのポインタを root とする。文字列Q内に存在する一つの文字(以下,対象文字という)をビット列に符号化して,整数(0~σ-1)に変換したものを r とする。
このとき,文字列Qの1文字目からm文字目までの部分文字列で,対象文字の出現回数を数える関数 rank(root,m,r) のプログラムを図3に示す。
文字の符号化に必要な最小のビット数は,大域変数 DEPTH に格納されているものとする。 〔ウェーブレット木の評価〕
〔ウェーブレット木の評価〕
文字列Qが与えられたとき,文字列Qの長さをN,文字の種類の個数をσとする。ここで,議論を簡潔にするためにσは2以上の2のべき乗とする。
文字列Qが与えられたときのウェーブレット木の構築時間は,文字ごとにlog2(ク)か所のノードで操作を行い,各ノードでの操作は定数時間で行うことができるので,合計でO(ケ×log2(ク))である。
構築されたウェーブレット木が保持するキー値のビット列の長さの総和は,コである。
例えば,DNAはA(アデニン),C(シトシン),G(グアニン),T(チミン)の4種類の文字の配列で表すことができ,その配列は長大になることが多いので,ウェーブレット木はDNAの塩基配列(以下,DNA配列という)の構造解析に適している。
ウェーブレット木において,文字の出現回数を数える操作と文字の出現位置を返す操作を組み合わせることによって,文字列の様々な操作を実現することができる。本問では,文字の出現回数を数える操作を扱う。
〔ウェーブレット木の構築〕
文字の種類の個数が4の場合を考える。DNA配列を例に文字列Pを"CTCGAGAGTA"とするとき,ウェーブレット木が構築される様子を図1に示す。
ここで,2分木の頂点のノードを根と呼び,子をもたないノードを葉と呼ぶ。根からノードまでの経路の長さ(経路に含まれるノードの個数-1)を,そのノードの深さと呼ぶ。各ノードにはキー値を登録する。
図1では,文字列Pの文字Aを00,文字Cを01,文字Gを10,文字Tを11の2ビットのビット列に符号化して,ウェーブレット木を構築する様子を示している。また,図1の文字列の振り分けは,ウェーブレット木によって文字列Pが振り分けられる様子を示している。
- 根(深さ0)を生成し,文字列Pを対応付ける。
- ノードに対応する文字列の各文字を表す符号に対して,ノードの深さに応じて決まるビット位置のビットの値を取り出し,文字の並びと同じ順番で並べてビット列として構成したものをキー値としてノードに登録する。ここで,ノードの深さに応じて決まるビット位置は,"左から(深さ+1)番目"とする。
ノードが根の場合は,ビット位置は左から(0+1=1)番目となるので,図2に示すように,文字列P"CTCGAGAGTA"に対応する根のキー値はビット列0101010110となる。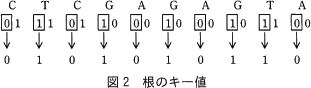
- キー値のビット列を左から1ビットずつ順番に見ていき,キー値の元になった文字列から,そのビットに対応する文字を,ビットの値が0の場合とビットの値が1の場合とで分けて取り出し,それぞれの文字を順番に並べて新たな文字列を作成する。
文字列Pに対応する根のキー値の場合は,ビットの値が0の場合の文字列として"CCAAA"を取り出し,ビットの値が1の場合の文字列として"イ"を取り出す。
ビットの値が0の場合に取り出した文字列内の文字が2種類以上の場合は,その文字列に対応する新たなノードを生成して,左の子ノードとする。取り出した文字列内の文字が1種類の場合は,新たなノードは生成しない。
ビットの値が1の場合に取り出した文字列内の文字が2種類以上の場合は,その文字列に対応する新たなノードを生成して,右の子ノードとする。取り出した文字列内の文字が1種類の場合は,新たなノードは生成しない。
生成した子ノードに対して,(2),(3)の処理を繰り返す。新たなノードが生成されなかった場合は,処理を終了する。
文字列P全体での文字C(=01)の出現回数は,次の(1),(2)の手順で求める。
- 文字Cの符号の左から1番目のビットの値は0なので,文字Cは根から左の子ノードに振り分けられる。左の子ノードに振り分けられる文字の個数は,根のキー値の0の個数に等しく,ウである。
- 文字Cの符号の左から2番目のビットの値は1である。(1)で振り分けられた左の子ノードのキー値の1の個数は2で,このノードは葉であるので,これが文字列P全体での文字Cの出現回数となる。
与えられた文字列Q内に含まれる文字の種類の個数をσとするとき,あらかじめ生成したウェーブレット木を用いて,与えられた文字列内で指定した文字の出現回数を数えるプログラムを考える。ウェーブレット木の各ノードを表す構造体 Node を表1に示す。左の子ノード,又は右の子ノードがない場合は,それぞれ,left,right にはNULLを格納する。
このとき,文字列Qの1文字目からm文字目までの部分文字列で,対象文字の出現回数を数える関数 rank(root,m,r) のプログラムを図3に示す。
文字の符号化に必要な最小のビット数は,大域変数 DEPTH に格納されているものとする。
文字列Qが与えられたとき,文字列Qの長さをN,文字の種類の個数をσとする。ここで,議論を簡潔にするためにσは2以上の2のべき乗とする。
文字列Qが与えられたときのウェーブレット木の構築時間は,文字ごとにlog2(ク)か所のノードで操作を行い,各ノードでの操作は定数時間で行うことができるので,合計でO(ケ×log2(ク))である。
構築されたウェーブレット木が保持するキー値のビット列の長さの総和は,コである。
広告
設問1
図1中のア,図1及び本文中のイに入れる適切な字句を答えよ。
解答例・解答の要点
ア:10001
イ:TGGGT
イ:TGGGT
解説
〔ウェーブレット木の構築〕では、各ノードに対応する文字列を決定してから、そのノードにキー値を登録するので、設問1では先にイの文字列を求めた後、その文字列をもとにアのキー値を求める流れになります。〔イについて〕
〔ウェーブレット木の構築〕(2)で得られたビット列「0101010110」を、続く(3)でビットの 0 と 1 に分けます。
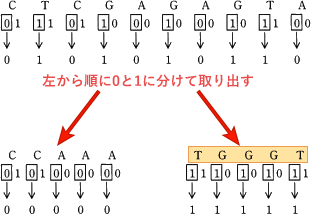
∴イ=TGGGT
〔アについて〕
右のノードに対応する文字列"TGGGT"からキー値を求めます。〔ウェーブレット木の構築〕(2)に従うと、キー値を得る手順は次の通りです。
- イの文字列"TGGGT"をビット列に符号化する
- ノードの深さに応じて決まるビット位置を求める
- 1.で求めたビット列から、文字の並びと同じ順番でビットを取り出し、アのキー値とする
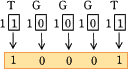
- 手順1
- 文字Gは10、文字Tは11ですから、文字列"TGGGT"をビット列に符号化すると「11 10 10 10 11」が得られます。
- 手順2
- 取り出すビット位置は、"左から(深さ+1)番目"です。アのノードの深さは1なので、ビット位置は「左から(1+1=)2番目」となります。
- 手順3
- 手順1で求めた「11 10 10 10 11」から、各文字ごとに左から2番目のビットを取り出します。
11 10 10 10 11 → 10001
広告
設問2
本文中のウに入れる適切な字句を答えよ。
解答例・解答の要点
ウ:5
解説
問題文には、「左の子ノードに振り分けられる文字の個数は,根のキー値の0の個数に等しく,ウである」と記述されています。設問1のイを求める手順でわかったように、ある文字が左のノードに振り分けられるか右のノードに振り分けられるかは、キー値のビット列が 0 か 1 によって決定されます。文字列Pの根のキー値「0101010110」のうち 0 の個数は5個なので、左のノードに振り分けられる文字の個数は5個になります(図1の"CCAAA"を見れば一目瞭然ですが...)。よってウには 5 が入ります。
∴5
広告
設問3
図3中のエ~キに入れる適切な字句を答えよ。
解答例・解答の要点
エ:DEPTH-d
オ:r
カ:0
キ:count
オ:r
カ:0
キ:count
解説
〔エオについて〕図3「関数rankのプログラム」の7行目のコメント行に「rに対応するビット列の左からd番目のビット位置のビットの値をbに格納」と書かれています。8行目から10行目は、この処理を行っている箇所です。
あるビット列から特定の位置のビットを取り出す場合は、以下の手順で処理を行います。
- 取り出したい位置のビットを 1、それ以外の位置のビットを 0 としたビット列を用意する
- 対象文字のビット列と、1.で用意したビット列の論理積(AND)を求める
- 2.で求めた論理積を右にビットシフトして、取り出したい位置のビットを取得する

また、d はプログラムの3行目と22行目の記述から、符号中の左からのビット位置を保持する変数であり、whileループを繰り返す(木構造を下がる)ごとに1、2、3、…と1ずつ増えていくことがわかります。
エは、手順1のビット列を用意するために「1を何ビット左にシフトすれば良いか」と考えます。具体例を挙げて、プログラムに落とし込む手順を踏むと、
- ビット列の長さが5、左から2番目を取り出す場合
- 用意するビット列は"01000"なので、1を左に3ビットシフトする
- ビット列の長さが5、左から3番目を取り出す場合
- 用意するビット列は"00100"なので、1を左に2ビットシフトする
- ビット列の長さが6、左から3番目を取り出す場合
- 用意するビット列は"001000"なので、1を左に3ビットシフトする
- ビット列の長さが6、左から2番目を取り出す場合
- 用意するビット列は"010000"なので、1を左に4ビットシフトする
オは、手順2に該当し、プログラムの8行目(手順1に相当)で作成したマスクビット列 x と論理積を求めるものですので、取り出し対象のビット列である r が入ります。
∴エ=DEPTH - d
オ=r
〔カについて〕
図3の10行目のコメントに「bは0か1の値」と書かれているので、カには0か1のどちらかが入ります。また、図3の17行目から、この条件式を満たす場合の処理は、「nodep ← nodep.left」であることがわかります。nodep.left は、左の子ノードへのポインタであり、次回のwhileループで左の子ノードを検索対象とする処理です。本問のウェーブレット木では、ある文字の指定位置から取り出したビットが 0 の場合には左の子ノードに、1 の場合には右の子ノードに振り分けるので、出現回数を数える対象となっている文字を格納する葉に行き着くためには、bが0の場合には左の子ノードへ、bが1の場合には右の子ノードへ進まなければなりません。よってカには 0 が入ります。
∴カ=0
〔キについて〕
図3の4行目から n は検索対象の文字列(キー値)の長さであることがわかります。このことから、プログラムの21行目は n の更新をする処理であり、キには次の検索対象の文字列の長さが入ることがわかります。次の検索対象となる文字列とは、現在のノードに振り分けられた文字列のうち、次にたどる(左又は右の)子ノードに振り分けられる文字列です。
次の検索対象となる子ノードの文字列長は、11行目から15行目の処理で求めています。具体的には、現在のノードのキー値の各ビットと b を比較して、一致する場合に変数 count を増やしています。何をしているかというと、出現回数を数える対象となっている文字と同じ子ノードに振り分けられる文字数を数えているのです。
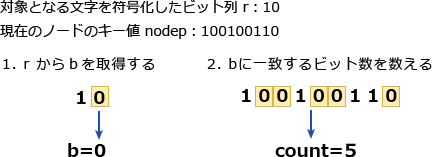
∴キ=count
広告
設問4
本文中のク~コに入れる適切な字句を答えよ。
解答例・解答の要点
ク:σ
ケ:N
コ:Nlog2(σ)
ケ:N
コ:Nlog2(σ)
解説
〔クについて〕ウェーブレット木の構築は、各文字ごとにルートから葉までのノードで操作を行います。ルートから葉までにたどるノードの数は、ウェーブレット木の深さと等しくなります。文字の種類の個数をσとすると、ウェーブレット木の深さは log2(σ) となるので、クには σ が入ります。
∴ク=σ
〔ケについて〕
各ノードでの操作に掛かる定数時間を考えます。プログラムを見ると、各ノードにはwhileループの中に記述された処理が1回だけ行われます。この中には、キー値全てを走査するfor文が1つ含まれているため、各ノードに対する計算量は O(N) (線形時間:データ量の分だけ時間を要する)になります。
∴ケ=N
〔コについて〕
ウェーブレット木全体のキー値の長さの総和は、「深さごとのキー値の長さの和×深さ」で求めることができます。
まず、深さごとのキー値の長さの和について考えます。
本問の図1を見てみると、深さ0のノード(根)のキー値は「0101010110」であり、長さは 10(=N) です。深さ1のノードのキー値の長さは、いずれも 5 です。
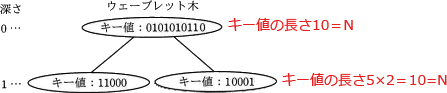
次に、ウェーブレット木の深さを求めます。これはクで求めたとおり、log2(σ)です。
以上より、
- 深さごとのキー値の長さの和:N
- ウェーブレット木の深さ:log2(σ)
∴コ=Nlog2(σ)
広告

広告