
応用情報技術者過去問題 平成23年秋期 午後問4
⇄問題文と設問を画面2分割で開く⇱問題PDF問4 システムアーキテクチャ
サーバの仮想化に関する次の記述を読んで,設問1~3に答えよ。
S社では,社内システムで使用しているサーバの電力使用量と設置スペースを削減するために,サーバの仮想化を検討することにした。そのための準備として,経理システムと人事システムを対象に,両システムのサーバの現状を調査した。調査結果を表1に示す。各サーバはCPU数とメモリ容量だけが異なっていた。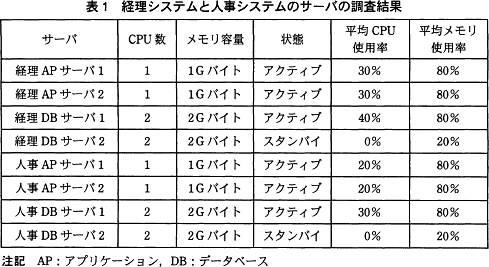 〔冗長構成の考え方〕
〔冗長構成の考え方〕
サーバ仮想化のホストサーバとなる物理サーバにはブレードを使用する。1枚のブレード上には,4コアのCPUを一つと,メモリを4Gバイト搭載している。1コア当たりの性能は,仮想化とマルチコアによるオーバーヘッドを考慮して,現行サーバのCPU一つと同等である。
〔サーバ仮想化の構成案〕
サーバ仮想化を検討する際,次の2点を前提とした。
表2の構成案1は,ブレード3を予備のブレードとして使用する案である。この構成では,ブレード1又はブレード2で障害が発生すると,各仮想サーバは〔冗長構成の考え方〕(1)に従って業務を継続する。その後,障害が発生したブレードに割り当てられていたディスクがブレード3に割り当てられ,ブレード3は,障害が発生したブレードと全く同じものとして起動される。元のブレード上で稼働していた仮想サーバも自動的に起動される。その際に起動される各仮想サーバは〔冗長構成の考え方〕(2)に従って動作する。 表3の構成案2は,ブレード3を両システムのAPサーバ2とDBサーバ2として使用する案である。ブレードで障害が発生すると,各仮想サーバは〔冗長構成の考え方〕(1)に従って業務を継続する。
表3の構成案2は,ブレード3を両システムのAPサーバ2とDBサーバ2として使用する案である。ブレードで障害が発生すると,各仮想サーバは〔冗長構成の考え方〕(1)に従って業務を継続する。 〔可用性〕
〔可用性〕
物理サーバのハードウェア障害に対する経理システムの可用性を考える。
現行のサーバ1台の可用性をpとし,DBサーバ障害時のフェイルオーバに要する時間は考えないものとすると,現行の経理システムの可用性は,
(1-(1-p)2)2
となる。
サーバ仮想化のホストサーバであるブレード1枚の可用性もpであるとすると,構成案1における経理システムの可用性はaであり,構成案2における経理システムの可用性はbである。ここで,予備のブレードで仮想サーバが起動するまでの時間については考えないものとする。
〔CPU使用率〕
各構成案のCPU使用率について,表1のCPU数と平均CPU使用率を基に算出した結果を表4に示す。どちらの構成案でもCPUは十分に余裕があり,性能は低下しないと言える。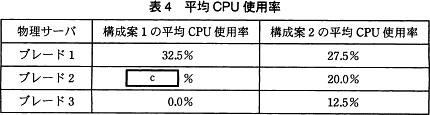 〔メモリ使用量〕
〔メモリ使用量〕
今回採用するサーバ仮想化の技術には,メモリオーバコミット機能があり,物理サーバに搭載されているメモリ容量を超えて仮想サーバにメモリを割り当てることが可能である。しかし,メモリ使用量が搭載量を超えると性能が低下するので,超えないようにしたい。
各構成案の通常時のメモリ使用量について,表1のメモリ容量と平均メモリ使用率を基に算出した結果を表5に示す。どちらの構成案でもメモリは足りており,性能は低下しないと言える。なお,仮想化によるメモリ使用量の増加はないものとする。
S社では,社内システムで使用しているサーバの電力使用量と設置スペースを削減するために,サーバの仮想化を検討することにした。そのための準備として,経理システムと人事システムを対象に,両システムのサーバの現状を調査した。調査結果を表1に示す。各サーバはCPU数とメモリ容量だけが異なっていた。
- 両システムとも,APサーバはアクティブ/アクティブの2台構成で負荷分散しており,どちらかのサーバで障害が発生した場合でも,残ったサーバによって,業務は停止することなく継続して行える。DBサーバは共有ディスク方式のアクテイブ/スタンバイ構成で,共有ディスクでDBを管理している。アクティブなDBサーバで障害が発生すると,スタンバイのDBサーバにフェイルオーバし,業務を継続する。
- 障害が発生したAPサーバが復旧すると,アクティブなAPサーバとして負荷分散に加わる。障害が発生したDBサーバが復旧すると,スタンバイのDBサーバとして,アクティブなDBサーバの障害に備える。
サーバ仮想化のホストサーバとなる物理サーバにはブレードを使用する。1枚のブレード上には,4コアのCPUを一つと,メモリを4Gバイト搭載している。1コア当たりの性能は,仮想化とマルチコアによるオーバーヘッドを考慮して,現行サーバのCPU一つと同等である。
〔サーバ仮想化の構成案〕
サーバ仮想化を検討する際,次の2点を前提とした。
- 前提1
- 物理,仮想を問わず,サーバに障害が発生した際に業務が停止する時間は,現行システムより長くならないこと。
- 前提2
- 性能は,障害発生時を除き,現行システムより低下しないこと。
表2の構成案1は,ブレード3を予備のブレードとして使用する案である。この構成では,ブレード1又はブレード2で障害が発生すると,各仮想サーバは〔冗長構成の考え方〕(1)に従って業務を継続する。その後,障害が発生したブレードに割り当てられていたディスクがブレード3に割り当てられ,ブレード3は,障害が発生したブレードと全く同じものとして起動される。元のブレード上で稼働していた仮想サーバも自動的に起動される。その際に起動される各仮想サーバは〔冗長構成の考え方〕(2)に従って動作する。
物理サーバのハードウェア障害に対する経理システムの可用性を考える。
現行のサーバ1台の可用性をpとし,DBサーバ障害時のフェイルオーバに要する時間は考えないものとすると,現行の経理システムの可用性は,
(1-(1-p)2)2
となる。
サーバ仮想化のホストサーバであるブレード1枚の可用性もpであるとすると,構成案1における経理システムの可用性はaであり,構成案2における経理システムの可用性はbである。ここで,予備のブレードで仮想サーバが起動するまでの時間については考えないものとする。
〔CPU使用率〕
各構成案のCPU使用率について,表1のCPU数と平均CPU使用率を基に算出した結果を表4に示す。どちらの構成案でもCPUは十分に余裕があり,性能は低下しないと言える。
今回採用するサーバ仮想化の技術には,メモリオーバコミット機能があり,物理サーバに搭載されているメモリ容量を超えて仮想サーバにメモリを割り当てることが可能である。しかし,メモリ使用量が搭載量を超えると性能が低下するので,超えないようにしたい。
各構成案の通常時のメモリ使用量について,表1のメモリ容量と平均メモリ使用率を基に算出した結果を表5に示す。どちらの構成案でもメモリは足りており,性能は低下しないと言える。なお,仮想化によるメモリ使用量の増加はないものとする。
設問1
経理システムの可用性について,(1),(2)に答えよ。
- 本文中のa,bに入れる適切な式を解答群の中から選び,記号で答えよ。
- 現行システム,構成案1及び構成案2を,可用性の最も高いものから降順に答えよ。解答する際は,"現行","1","2" を記入すること。
a,b に関する解答群
- 1-(1-p)2
- 1-(1-p)3
- (1-(1-p)2)2
- (1-(1-p)2)3
- (1-(1-p)3)2
- (1-(1-p)3)3
解答入力欄
- a:
- b:
- o:
解答例・解答の要点
- a:イ
- b:ア
- o:1>2>現行
解説
- 〔aについて〕
構成案1では、ブレード1・ブレード2・ブレード3のうち、少なくとも1つが正常に動作していれば、経理システムは正常に稼働し続けられます。言い換えると、3台のブレードで同時に障害が発生したときのみ経理システムは稼働できなくなります。- 1台のブレードで障害が発生する確率:1-p
- 3台のブレードで同時に障害が発生する確率(経理システムの不稼働率):(1-p)3
∴a=イ:1-(1-p)3
〔bについて〕
構成案2では、ブレード1・ブレード3のうち、少なくとも1つが正常に動作していれば、経理システムは正常に稼働し続けれらます(経理システムのサーバが載っていないブレード2は無関係)。
[a]と同様の考え方で、経理システムの不稼働率は「(1-p)2」、経理システムの可用性は、1から不稼働率を引いた「1-(1-p)2」です。
∴b=ア:1-(1-p)2
※可用性 p の機器 n 台が並列接続されているとき、全体の可用性は 1-(1-p)n で表すことができます。 - (1)で算出した結果、各構成の可用性は以下のとおりです。
- 現行システム:(1-(1-p)2)2
- 構成案1:1-(1-p)3
- 構成案2:1-(1-p)2
- 現行システム:(1-(1-0.9)2)2=(1-0.01)2=0.992=0.9801
- 構成案1:1-(1-0.9)3=1-0.001=0.999
- 構成案2:1-(1-0.9)2=1-0.01=0.99
∴1>2>現行
設問2
表4中のcに入れる適切な数値を答えよ。答えは,小数第1位まで求めよ。
解答入力欄
- c:%
解答例・解答の要点
- c:27.5
解説
構成案1のブレード2の平均CPU使用率を計算する問題です。
まずは、ブレード2に載っている仮想サーバのCPU使用率の合計を求めます。
したがって、ブレード2の平均CPU使用率は、
110÷400=0.275=27.5%
したがって[c]には「27.5」が当てはまります。
∴c=27.5
※110%を4つのコアで処理するので「110%÷4=27.5%」と考えてもいいでしょう。
まずは、ブレード2に載っている仮想サーバのCPU使用率の合計を求めます。
- 経理APサーバ2:30%×1CPU=30
- 経理DBサーバ2:0%×2CPU=0
- 人事APサーバ1:20%×1CPU=20
- 人事DBサーバ1:30%×2CPU=60
したがって、ブレード2の平均CPU使用率は、
110÷400=0.275=27.5%
したがって[c]には「27.5」が当てはまります。
∴c=27.5
※110%を4つのコアで処理するので「110%÷4=27.5%」と考えてもいいでしょう。
設問3
構成案1では,ブレード1で障害が発生すると,ブレード1上で稼働していた仮想サーバがブレード3で稼働することになる。このとき,ブレード2のメモリ使用量が搭載しているメモリ容量を超えてしまう。その理由を35字以内で述べよ。また,このとき何Gバイトのメモリが不足するかを答えよ。
解答入力欄
- 理由:
- 不足:Gバイト
解答例・解答の要点
- 理由:
経理DBサーバ2がスタンバイ状態からアクティブ状態になるから (30文字) - 不足:0.8
解説
問題文の〔冗長構成の考え方〕に「DBサーバは共有ディスク方式のアクテイブ/スタンバイ構成で,共有ディスクでDBを管理している。アクティブなDBサーバで障害が発生すると,スタンバイのDBサーバにフェイルオーバし,業務を継続する」という記載があります。
この記述より、ブレード1で障害が発生するとアクティブな経理DBサーバ1が停止し、ブレード2のスタンバイの経理DBサーバ2がアクティブに切り替わることがわかります。 表5に記載の構成案1におけるブレード2の平均メモリ使用量は、下記のとおり、経理DBサーバ2がスタンバイ状態であることを前提に算定されています。
表5に記載の構成案1におけるブレード2の平均メモリ使用量は、下記のとおり、経理DBサーバ2がスタンバイ状態であることを前提に算定されています。
∴理由:経理DBサーバ2がスタンバイ状態からアクティブ状態になるから
不足:0.8(Gバイト)
この記述より、ブレード1で障害が発生するとアクティブな経理DBサーバ1が停止し、ブレード2のスタンバイの経理DBサーバ2がアクティブに切り替わることがわかります。
- 経理APサーバ2:1GB×80%=0.8GB
- 経理DBサーバ2:2GB×20%=0.4GB(★)
- 人事APサーバ1:1GB×80%=0.8GB
- 人事DBサーバ1:2GB×80%=1.6GB
- 合計:3.6GB
∴理由:経理DBサーバ2がスタンバイ状態からアクティブ状態になるから
不足:0.8(Gバイト)
