
応用情報技術者過去問題 平成27年秋期 午後問6
⇄問題文と設問を画面2分割で開く⇱問題PDF問6 データベース
人事情報のデータ構造に関する次の記述を読んで,設問1~3に答えよ。
R社では,人事システムの改善を検討している。現行システムでは,現時点での情報しか管理していないが,過去の履歴や将来の発令予定も管理できるようにしたいと考えている。
現行システムでの社員と部署のE-R図を図1に示す。部署の階層は木構造になっており,再帰リレーションシップで表現している。最上位は会社で,下に向かって本部,部,課などが配置されている。上位部署IDには,上位部署の部署IDを保持し,最上位である会社の上位部署IDにはNULLを設定する。社員は必ず一つの部署だけに所属している。部署には部署長が必ず一人存在するが,一人の社員が複数の部署の部署長を兼任している場合もある。また,各社員に携帯電話機を1台ずつ配布しており,電話番号は部署にではなく,社員に割り当てられている。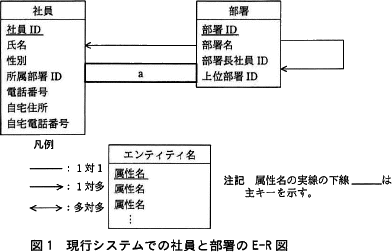 図1のリレーションシップが,どの属性と関連しているかを表1に示す。表1の1行目は,エンティティ"社員"の属性"所属部署ID"がエンティティ"部署"の属性"部署ID"を参照する外部キーとなっていて,"社員"と"部署"の間には多対1のリレーションシップがあることを示している。多対1のリレーションシップの多側が外部キーの属性,1側が主キーの属性と対応している。
図1のリレーションシップが,どの属性と関連しているかを表1に示す。表1の1行目は,エンティティ"社員"の属性"所属部署ID"がエンティティ"部署"の属性"部署ID"を参照する外部キーとなっていて,"社員"と"部署"の間には多対1のリレーションシップがあることを示している。多対1のリレーションシップの多側が外部キーの属性,1側が主キーの属性と対応している。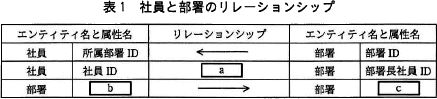 現行システムは,図1のE-R図のエンティティ名を表名に,属性名を列名にして,適切なデータ型で表定義した関係データベースによって,データを管理している。
現行システムは,図1のE-R図のエンティティ名を表名に,属性名を列名にして,適切なデータ型で表定義した関係データベースによって,データを管理している。
指定した部署とその配下の全ての部署の部署ID,部署名,上位部署IDを出力するSQL文を図2に示す。ここで,":部署ID"は,指定した部署の部署IDを格納する埋込み変数である。 図2では,SQL:1999で導入された WITHRECURSIVE 構文を用いて再帰的なクエリを実現している。まず2,3行目の SELECT で,埋込み変数":部署ID"で指定し上位部署IDから成る1行の表"関連部署"が導出される。次に5,6行目の SELECT で,"関連部署"の中にある部署IDと一致する上位部署IDをもつ部署の部署ID,部署名,上位部署IDから成る行の集まりが新たに表"関連部署"として導出される。これが,表"関連部署"の新たな行がなくなるまで繰り返される。最後に8行目の SELECT で,それまで導出された"関連部署"の全ての行について部署ID,部署名,上位部署IDが出力される。
図2では,SQL:1999で導入された WITHRECURSIVE 構文を用いて再帰的なクエリを実現している。まず2,3行目の SELECT で,埋込み変数":部署ID"で指定し上位部署IDから成る1行の表"関連部署"が導出される。次に5,6行目の SELECT で,"関連部署"の中にある部署IDと一致する上位部署IDをもつ部署の部署ID,部署名,上位部署IDから成る行の集まりが新たに表"関連部署"として導出される。これが,表"関連部署"の新たな行がなくなるまで繰り返される。最後に8行目の SELECT で,それまで導出された"関連部署"の全ての行について部署ID,部署名,上位部署IDが出力される。
〔新システムでの履歴管理〕
新システムでは,(1)~(4)の要件を実現したいと考えている。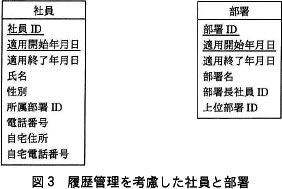 しかし,①図3のエンティティ"社員"は十分に正規化されていないとの指摘を受け,エンティティ"所属"を新たに追加し,エンティティ"社員"を第3正規形とした。新システムでの社員と部署と所属のE-R図を図4に示す。
しかし,①図3のエンティティ"社員"は十分に正規化されていないとの指摘を受け,エンティティ"所属"を新たに追加し,エンティティ"社員"を第3正規形とした。新システムでの社員と部署と所属のE-R図を図4に示す。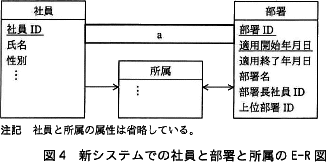 要件(2)を実現するSQL文を図5に示す。ここで,":年月日"は,指定した日の日付を格納する埋込み変数である。
要件(2)を実現するSQL文を図5に示す。ここで,":年月日"は,指定した日の日付を格納する埋込み変数である。 現時点での部署テーブルの内容を表2に示す。
現時点での部署テーブルの内容を表2に示す。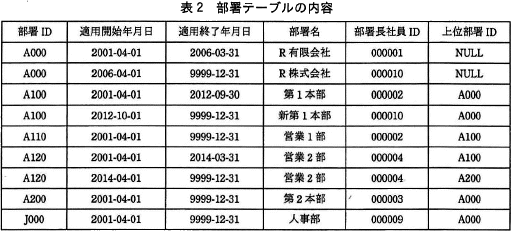 埋込み変数":年月日"にeからfまでの範囲の日付を設定して,表2の部署テーブルに対して図5のSQL文を実行すると,その結果は表3のとおりとなる。
埋込み変数":年月日"にeからfまでの範囲の日付を設定して,表2の部署テーブルに対して図5のSQL文を実行すると,その結果は表3のとおりとなる。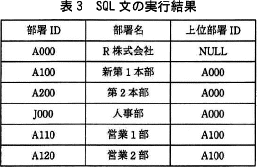
R社では,人事システムの改善を検討している。現行システムでは,現時点での情報しか管理していないが,過去の履歴や将来の発令予定も管理できるようにしたいと考えている。
現行システムでの社員と部署のE-R図を図1に示す。部署の階層は木構造になっており,再帰リレーションシップで表現している。最上位は会社で,下に向かって本部,部,課などが配置されている。上位部署IDには,上位部署の部署IDを保持し,最上位である会社の上位部署IDにはNULLを設定する。社員は必ず一つの部署だけに所属している。部署には部署長が必ず一人存在するが,一人の社員が複数の部署の部署長を兼任している場合もある。また,各社員に携帯電話機を1台ずつ配布しており,電話番号は部署にではなく,社員に割り当てられている。
指定した部署とその配下の全ての部署の部署ID,部署名,上位部署IDを出力するSQL文を図2に示す。ここで,":部署ID"は,指定した部署の部署IDを格納する埋込み変数である。
〔新システムでの履歴管理〕
新システムでは,(1)~(4)の要件を実現したいと考えている。
- 指定した社員が,今までに所属していた部署の履歴が分かる。
- 指定した日の,会社全体の部署構造が分かる。
- 人事異動後の部署,所属の情報をあらかじめ入力しておき,異動が発生したらすぐに有効とする。
- 所属情報以外の社員の情報は履歴管理する必要はなく,最新の情報だけを管理すればよい。
設問1
現行システムについて,(1),(2)に答えよ。
- 図1及び表1中のaに入れる適切なリレーションショプを答え,E-R図を完成させよ。図1の凡例に倣って解答すること。
- 表1中のb,cに入れる適切な属性名を答えよ。
解答入力欄
- a:
- b:
- c:
解答例・解答の要点
- a:→
- b:部署ID
- c:上位部署ID
解説
- 〔aについて〕
社員エンティティの主キー"社員ID"と、部署エンティティの属性"部署長社員ID"の関係を考えると、部署エンティティの属性"部署長社員ID"は社員エンティティの主キーを参照する外部キーであると考えられます。また、本文中には「部署には部署長が必ず一人存在するが,一人の社員が複数の部署の部署長を兼任している場合もある」とあり、1つの社員エンティティが複数の部署エンティティに関連し得ることがわかります。つまり、部署エンティティには同一の社員ID(部署長社員ID)の値を持つ複数のレコードが存在するということです。したがって、社員エンティティと部署エンティティのカーディナリティ(部署と部署長の関係)は1対多であり、[a]には「→」が当てはまります。
※原則として、ある主キーをもつエンティティと、その主キーを外部キーに持つエンティティのカーディナリティ(多重度)は「1対多」になります。
∴a=→ - 〔b、cについて〕
図1及び表1より部署エンティティには自己参照の関係があることがわかります。ここでいう自己参照とは、ある部署エンティティが別の部署エンティティに関連し得るということです。R社の部署の階層は木構造になっているので、1つの上位部署の下に複数(0以上)の下位部署が配置され、1つの上位部署は複数の下位部署と関連を持ちます。つまり、部署エンティティには同一の上位部署IDの値を持つ複数のレコードが存在するということです。
図1を見ると[b]側が"1"、[c]側が"多"の1対多のリレーションシップになっていますが、1対多の関係においては「1」側は主キーである必要があります。したがって、[b]には「部署ID」が当てはまります。
また、本文中に「上位部署IDには,上位部署の部署IDを保持し」とあることから、属性"上位部署ID"は主キー"部署ID"を参照する外部キーであることがわかります。したがって、[c]には「上位部署ID」が当てはまります。
∴b=部署ID
c=上位部署ID
設問2
新システムの要件を実現するためのエンティティについて,(1),(2)に答えよ。
- 本文中の下線①で,エンティティ"社員"は第1正規形,第2正規形,第3正規形のうち,どこまで正規化されているか答えよ。また,その理由を30字以内で述べよ。
- 図4中のエンティティ"所属"の属性を,本文中又は図中の字句を用いて答えよ。属性が主キーの一部となる場合は,実線の下線を付けること。
(※正誤判定の都合上、主キー属性は{属性名}と入力してください)
解答入力欄
- 正規形:
- 理由:
解答例・解答の要点
- 正規形:第1正規形
- 理由:・主キーの一部に関数従属している属性があるから (22文字)
・主キーに部分従属している属性があるから (19文字)
・社員IDだけに従属している属性があるから (20文字)
- 社員ID,適用開始年月日,適用終了年月日,所属部署ID
解説
- まず、各正規形について条件を確認します。
- 第1正規形
- 各属性の繰り返し項目を排除し、単一値を属性とする複数の行に分解した状態。
- 第2正規形
- 第1正規形であり、かつ、主キーの一部だけで一意に決まる属性を別表に分離した状態(主キーに部分関数従属する属性がない状態)。
- 第3正規形
- 第2正規形であり、かつ、主キー以外の属性によって一意に決まる属性を別表に分離した状態(主キーからの推移的関数従属が存在しない状態)。
次に社員エンティティが第2正規形かどうかを検討します。〔新システムでの履歴管理〕の要件(4)には「所属情報以外の社員の情報は履歴管理する必要はなく,最新の情報だけを管理すればよい」とあり、複合主キーの一部である"社員ID"がわかれば、属性"氏名"・"性別"・"電話番号"・"自宅住所"・"自宅電話番号"は一意に特定できます。複合主キーの一部に関数従属する属性がある(主キーに部分従属する属性がある)ことから、社員エンティティは第2正規形ではありません。
よって、社員エンティティは「第1正規形」、理由は「主キーの一部である関数従属する属性があるから」「主キーに部分従属している属性があるから」「社員IDだけに従属している属性があるから」などです。厳密には、第1正規形を充足し第2正規形でないことを説明する必要があるので、「すべての属性が単一値であること」「主キーの一部である"社員ID"に関数従属する属性があること」の2つを含める必要があるのですが、文字数制限の関係もあり解答例では後者の理由のみに留めています。
∴主キーの一部に関数従属している属性があるから
主キーに部分従属している属性があるから
社員IDだけに従属している属性があるから - 本文中に「エンティティ"所属"を新たに追加し,エンティティ"社員"を第3正規形とした」とあるので、図3の社員エンティティを第3正規形にすることを考えます。
図3の社員エンティティは第1正規形ですので、第3正規形にするためには、まず第2正規形にする必要があります。そのために、複合主キーへの部分関数従属を排除します。(1)より、属性"氏名"・"性別"・"電話番号"・"自宅住所"・"自宅電話番号"は複合主キーの一部である"社員ID"に関数従属しているため、"社員ID"を主キーとする新たなエンティティを作り、"社員ID"に関数従属する属性を移動します。図4より、このエンティティを改めて社員エンティティ、元のエンティティを所属エンティティとしていることがわかります。関係スキーマ:エンティティ名(属性名1,属性名2,...)を記述すると、社員(社員ID,氏名、性別、電話番号、自宅住所、自宅電話番号)となり、第2正規形です。次に所属エンティティが第3正規形かどうかを検討します。第3正規形では主キーではない属性への関数従属を排除します。属性"適用終了年月日"と"所属部署ID"の間に関数従属性がないことは明らかですので、推移適関数従属はありません。よって、第3正規形の条件を満たしています。
所属(社員ID,適用開始年月日,適用終了年月日,所属部署ID)
したがって、所属エンティティの属性は以下の4つです。
∴社員ID
適用開始年月日
適用終了年月日
所属部署ID
※図4より、第2正規形の段階からエンティティの個数が増えていないので、同時に第3正規形であったことは(裏技的に)一応わかります。
設問3
新システムの要件(2)について,(1),(2)に答えよ。
- 図5中のdに入れる適切な字句又は式を答えよ。
- 本文中のe,fに入れることのできる最大範囲の日付の組を答えよ。
解答入力欄
- d:
- e:
- f:
解答例・解答の要点
- d:IS NULL
- e:2012-10-01
- f:2014-03-31
解説
- 〔dについて〕
図5のSQL文は、図2で例示されているSQL文に日付指定の条件を追加した以外は基本的に違いはありません。ただし、UNION ALL句直前のWHERE句で指定している列が部署ID列から上位部署ID列に変わっています。UNION ALL句直後のSELECT文では、WITH RECURSIVE句で導出した関連部署表のレコードを順番に呼び出します。
図2のSQL文は、指定した部署とその配下の全ての部署を表示するものでしたから、会社全体の部署構造を表示するには木構造の最上位である"会社"を起点として指定することになります。本文中には「最上位である会社の上位部署IDにはNULLを設定する」とあるので、最初の関連部署表となる1行としては上位部署IDがNULLのレコードが適切です。したがって、[d]には「IS NULL」が当てはまります。
∴d=IS NULL - 〔e,fについて〕
表3の実行結果の各レコードは、以下の表2のレコードが選択されたものです。これらのレコードの適用開始年月日と適用終了年月日に注目します。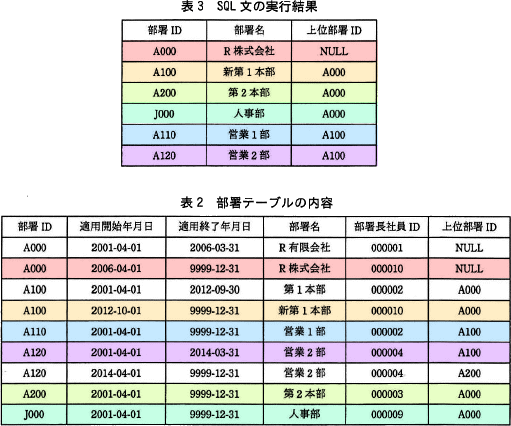 共通する期間を求めると2012-10-01以降、2014-03-31以前です。したがって、[e]には「2012-10-01」、[f]には「2014-03-31」が当てはまります。
共通する期間を求めると2012-10-01以降、2014-03-31以前です。したがって、[e]には「2012-10-01」、[f]には「2014-03-31」が当てはまります。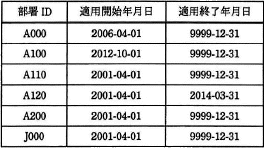
∴e=2012-10-01
f=2014-03-31
